





In today’s hyper-connected industrial ecosystems, network downtime translates to six-figure losses per hour in sectors like manufacturing, energy, and transportation. At the heart of operational resilience lies Mean Time Between Failures (MTBF)—a statistical lifeline that quantifies the reliability of Industrial Ethernet networks. As these networks evolve into critical infrastructure, understanding and optimizing MTBF transcends technical preference to become an economic imperative. This article examines why MTBF is the cornerstone of industrial reliability and how engineers can leverage it to build networks capable of surviving harsh realities.
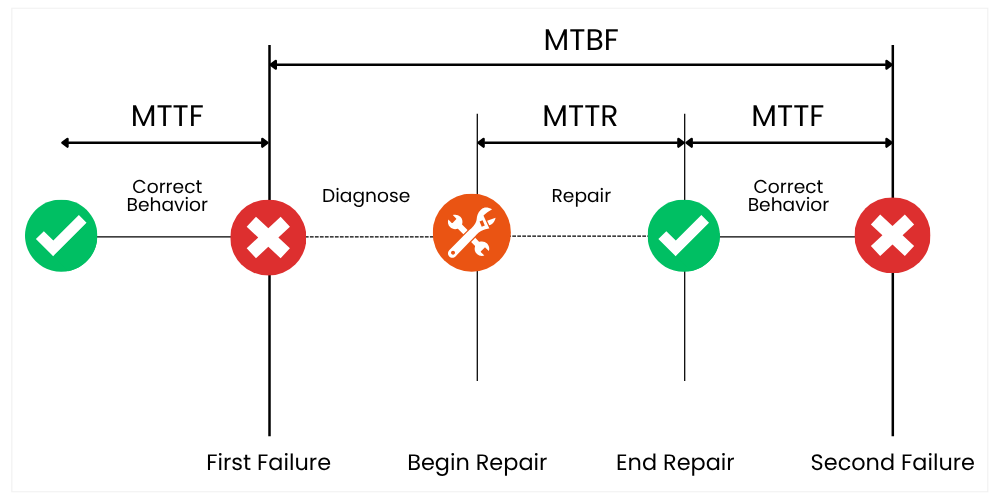
MTBF measures the reliability of repairable assets, indicating the average time between failures. This metric is invaluable for scheduling preventive maintenance and improving operational efficiency.
Defining MTBF in Industrial Contexts
MTBF measures the average operational time between inherent failures of a system or component, calculated by dividing total operational hours by the number of failures. For Industrial Ethernet switches operating in environments with extreme temperatures, vibration, or chemical exposure, MTBF isn’t merely a metric—it’s a design philosophy. Unlike consumer electronics, industrial networks demand MTBF values spanning decades rather than years. For instance, high-reliability switches target MTBF ratings exceeding 500,000 hours (57 years), ensuring alignment with 10+ year lifecycles of industrial assets.
The Bathtub Curve Context:
MTBF specifically addresses the “useful life” phase of the reliability bathtub curve, where random failures occur at a constant rate. This phase excludes early-life infant mortality and end-of-life wear-out, focusing purely on predictable operational reliability.
Thermal Management: The Invisible MTBF Assassin
Temperature remains the dominant factor influencing MTBF in Industrial Ethernet hardware. Studies confirm the “10°C Rule”: every 10°C rise in operating temperature halves the lifespan of electronic components. This relationship transforms thermal design into an MTBF optimisation battlefield:
- Passive vs. Active Cooling Trade-offs:
Passive (fanless) systems eliminate moving parts but risk internal heat accumulation. Tests show compact rack-mounted switches using natural convection can experience internal temperatures 40°C above ambient, pushing components toward the 85°C threshold where failure rates spike. By contrast, fan-cooled systems maintain only 15°C above ambient but introduce fans with finite 20,000-hour lifespans (≈2.28 years). - Smart Thermal Mitigation:
Advanced designs deploy intelligent fan controllers that dynamically adjust cooling based on load and ambient conditions. This reduces dust ingress, noise, and power consumption while extending fan life by 40% versus always-on systems. For passive systems, copper heatsinks, micro-forged fins, and convection-optimised layouts dissipate heat without reliability trade-offs.
| Ambient Temperature | Passive Cooling MTBF | Active Cooling MTBF |
| 30℃ | 10 years | 8 years |
| 50℃ | <8 years | 7 years |
Network Architecture: Amplifying Device-Level MTBF
Even high-MTBF devices fail. Network-level strategies transform individual weaknesses into systemic strength:
- Topology Diversity:
Ring protocols like RSTP or MRP create self-healing loops that bypass failed switches within 20ms—far faster than human response. - Predictive Maintenance:
Switches with embedded sensors track temperature, fan speed, and packet errors. Analytics platforms like Fiberroad’s Preview correlate anomalies with MTBF degradation patterns, triggering maintenance before failures.
| Protocol | Convergence Time | Impact on System Availability |
| STP/RSTP | 1-30 seconds | Low |
| MRP | <20ms | High |
Key Factors Enhancing Industrial Ethernet Switch Reliability
While MTBF quantifies hardware reliability, achieving industrial resilience demands a systemic mindset:
- Industrial-Grade Components: Using capacitors, resistors, ICs, connectors, etc., specifically rated for extended temperature ranges, higher vibration, and longer operational life compared to commercial-grade parts.
- Robust Power Supply Design: Dual/redundant power inputs (often with wide voltage ranges like 12-48VDC or 24-240VAC/DC), high efficiency, and strong protection against surges, spikes, and reverse polarity. Power supply failure is a common cause of downtime.
- Enhanced Electrical Protection:
- Surge Protection (IEC 61000-4-5): Protects data lines (Ethernet) and power lines from voltage surges (e.g., lightning, motor switching).
- ESD Protection (IEC 61000-4-2): Guards against electrostatic discharge.
- EFT/Burst Protection (IEC 61000-4-4): Protects against fast transient bursts (e.g., relay switching).
- Mechanical Robustness: Heavy-duty metal housings, secure mounting options (DIN-rail is standard), and vibration/shock resistance (e.g., IEC 60068-2-6 vibration, IEC 60068-2-27 shock).
Conclusion: Reliability as a Culture
MTBF is more than a datasheet number—it’s the crystallisation of rigorous design, validation, and operational discipline. In Industrial Ethernet networks, where failures cascade into production halts or safety incidents, the pursuit of optimal MTBF becomes non-negotiable. By embracing thermal-aware engineering, redundant architectures, and predictive analytics, industries can transform MTBF from an abstract statistic into a tangible shield against downtime. As thermal densities rise and IIoT expands, tomorrow’s networks will demand not just higher MTBF values but smarter frameworks for sustaining reliability through the entire operational journey. The era of “set-and-forget” networking is over; welcome to the age of reliability by design.